基于Hadoop平台的电信客服数据处理与分析系统 数据处理服务助你突破毕设难关
对于许多计算机科学与技术专业的学生来说,大数据毕设是一项挑战,尤其是基于Hadoop平台的电信客服数据处理与分析系统。如果你正为此苦恼,不必慌张,本文将指导你如何构建一个完整的系统,重点关注数据处理服务,帮助你顺利完成任务。
问题背景与挑战
大数据毕设通常要求处理海量数据,而电信客服数据具有高维度、实时性强和多样性等特点。常见的难点包括:数据清洗困难、Hadoop平台配置复杂、性能优化不足以及缺乏实际应用场景。这些因素可能导致学生无从下手,影响毕设进度。
解决方案:构建基于Hadoop的电信客服数据处理与分析系统
本系统以Hadoop生态系统为核心,结合MapReduce、Hive和Spark等工具,实现客服数据的采集、存储、处理和分析。以下是关键步骤:
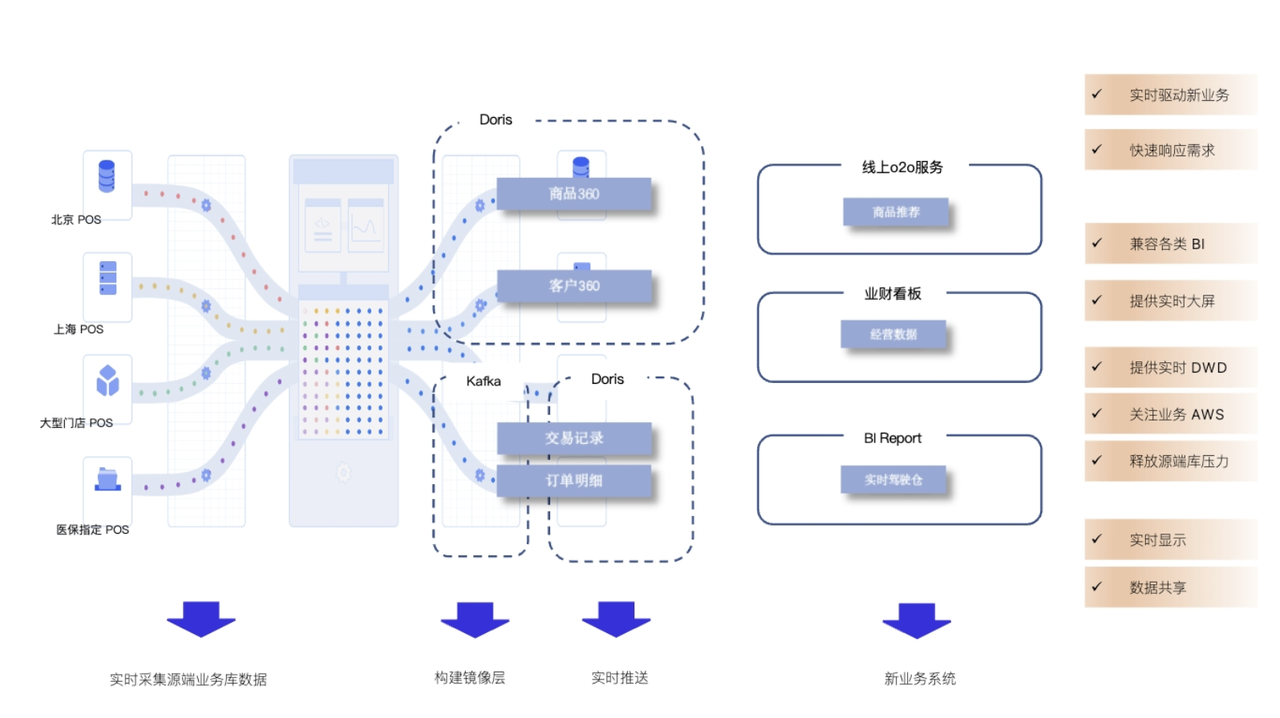
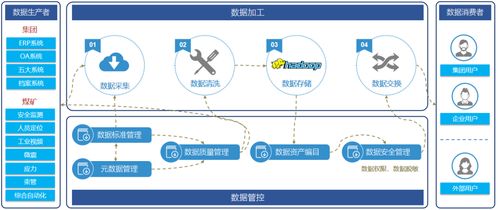
- 系统架构设计:采用分层架构,包括数据采集层(如Flume或Kafka)、数据存储层(HDFS)、数据处理层(MapReduce/Spark)和数据分析层(Hive/可视化工具)。这确保了系统的扩展性和高效性。
- 数据处理服务详解:
- 数据采集与清洗:使用Flume从电信客服日志中收集数据,并通过MapReduce或Spark进行预处理,去除噪音、处理缺失值,并转换为结构化格式。例如,可以过滤无效呼叫记录,确保数据质量。
- 数据存储与管理:将清洗后的数据存储在HDFS中,利用Hive建立数据仓库,便于后续查询。Hive的SQL-like语法简化了复杂查询,适合学生快速上手。
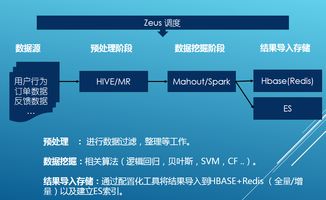
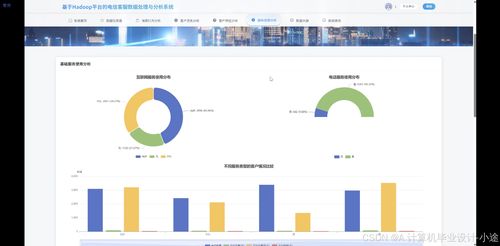
- 数据分析与挖掘:通过Spark MLlib或MapReduce实现关键分析,如呼叫量趋势、客户满意度分析和异常检测。举例来说,你可以计算高峰时段的客服负载,为电信公司优化资源提供依据。
- 性能优化:调整Hadoop配置参数(如块大小和副本数),使用压缩技术减少存储开销,并通过并行处理提升速度。这能帮助你在毕设中展示系统的高效性。
- 实践建议与工具推荐:
- 使用Cloudera或Hortonworks发行版简化Hadoop部署。
- 结合Python或Java编写MapReduce程序,利用开源数据集(如电信行业公开数据)进行测试。
- 关注数据处理服务的实时性,例如集成Storm或Flink处理流数据,以增强系统实用性。
突破难关的技巧
- 分阶段实施:先从数据采集和清洗入手,逐步扩展到复杂分析,避免一次性处理所有问题。
- 求助资源:参考Apache官方文档、在线教程(如Coursera的大数据课程)和开源项目,加入社区论坛获取帮助。
- 测试与迭代:在虚拟环境中反复测试,使用日志分析工具监控性能,确保系统稳定。
通过上述方法,你可以构建一个功能完整的电信客服数据处理与分析系统。这不仅帮助完成毕设,还能提升实际技能,为未来职业发展打下基础。记住,数据处理服务是核心,专注于它,你就能突破难关!
如若转载,请注明出处:http://www.jumeiguang.com/product/15.html
更新时间:2026-02-24 13:07:38